Further fidelity measures
Motivation
# https://cran.r-project.org/web/packages/sjPlot/vignettes/plot_likert_scales.html
# Recode variable
app_stats_lab = data.frame(lapply(app_stats, factor, ordered = TRUE, levels = 1:5,
labels = c("Do not agree", "Rather not agree", "Partly agree", "Rather agree",
"Agree")))
app_stats_lab$group = app_stats$group
# Separate by training / control group
app_stats_ZE = app_stats_lab[app_stats_lab$group == "Zirkus Empathico", ]
app_stats_SB = app_stats_lab[app_stats_lab$group == "Controls", ]
app_stats_ZE = subset(app_stats_ZE, select = -c(group))
app_stats_SB = subset(app_stats_SB, select = -c(group))
# Create main plot
ZE_fidel = plot_likert(app_stats_ZE, catcount = 5, values = FALSE, wrap.legend.labels = 5,
geom.colors = c("#f0c99d", "#e1943a", "#d97909", "#6d3d05", "#2b1802"), rel_heights = c(8,
12), title = "Zirkus Empathico", wrap.labels = 65, reverse.scale = TRUE,
show.n = FALSE, axis.labels = c("", "", "", "", "", "", "", "")) + theme_bw() +
theme(legend.position = "bottom", panel.grid.major.x = element_line(color = "grey"),
panel.grid.major.y = element_line(colour = "grey"), panel.border = element_blank(),
axis.ticks.y = element_blank(), axis.ticks.x = element_blank(), axis.text.x = element_text(size = 5),
legend.text = element_text(size = 4), legend.key.size = unit(0.3, "cm"))
CT_fidel = plot_likert(app_stats_SB, catcount = 5, values = FALSE, wrap.legend.labels = 5,
geom.colors = c("#dbdbdb", "#b7b7b7", "#878787", "#515151", "#1b1b1b"), rel_heights = c(8,
12), title = "Controls", wrap.labels = 65, reverse.scale = TRUE, show.n = FALSE,
legend.labels = NULL, axis.labels = c("My child enjoyed the training.", "My child was motivated to do the training.",
"My child trained mostly without me.", "The training was self-explanatory.",
"The training was compatible with daily routines.", "My child copes better with its own feelings.",
"My child is more interested in other languages.")) + theme_bw() + theme(legend.position = "bottom",
panel.grid.major.x = element_line(color = "grey"), panel.grid.major.y = element_line(colour = "grey"),
panel.border = element_blank(), axis.ticks.y = element_blank(), axis.ticks.x = element_blank(),
axis.text.x = element_text(size = 5), legend.text = element_text(size = 4), legend.key.size = unit(0.3,
"cm"))
fig_fidel = cowplot::plot_grid(CT_fidel, ZE_fidel, nrow = 1, rel_widths = c(1, 0.45))
fig_fidel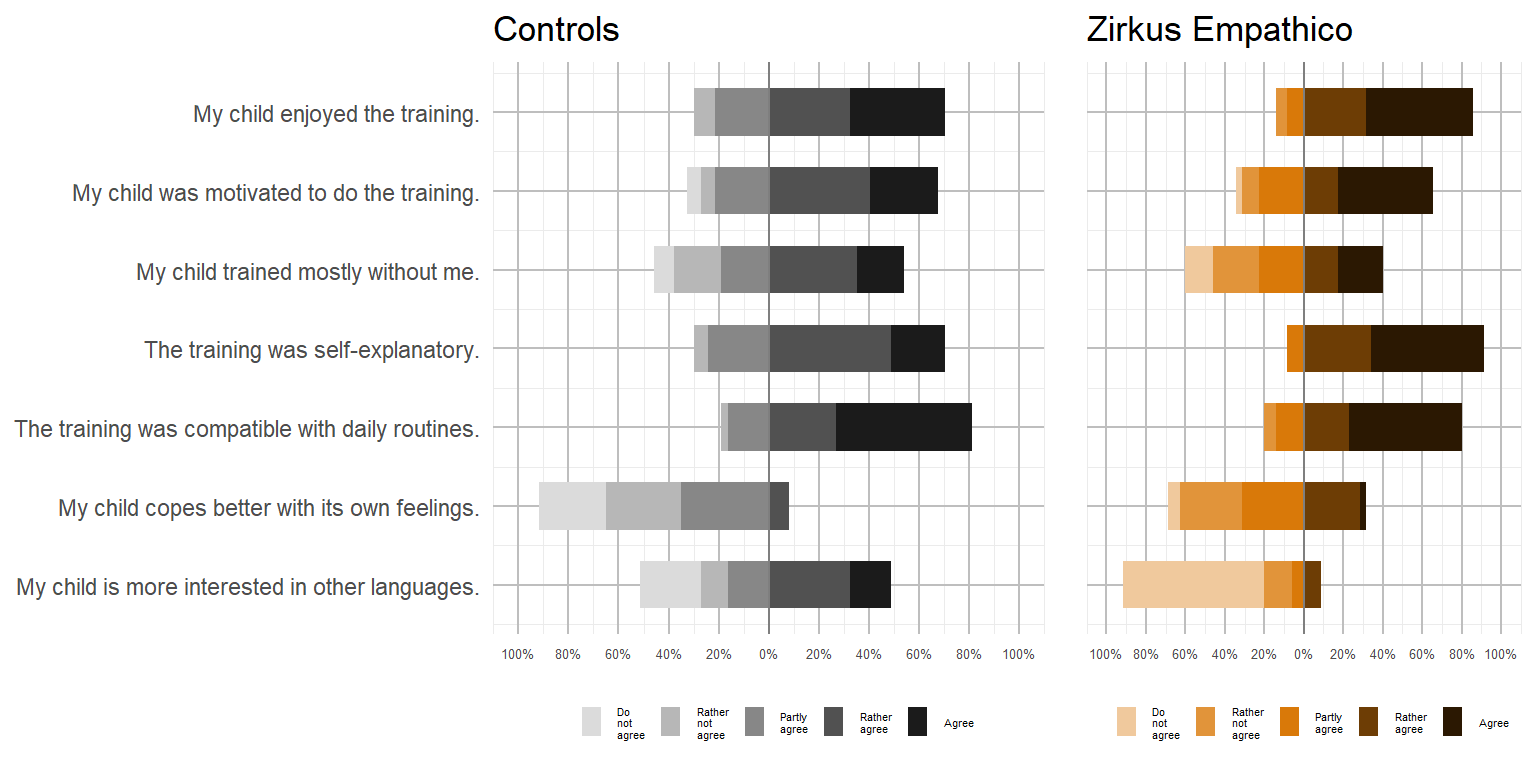
# Apply labels
app_stats = apply_labels(app_stats,
Fun = "My child enjoyed the training.",
Motivation = "My child was motivated to do the training.",
Practiced_without_parent = "My child trained mostly without me.",
Use_App_self_explanatory = "The training was self-explanatory.",
Use_Training_daily_life = "The training was compatible with daily routines.",
Behav_Dealing_w_Feelings = "My child copes better with its own feelings.",
Behav_Interest_Languages = "My child is more interested in other languages")
# Prepare table
app_stats_table =
tbl_summary(
app_stats ,
by = group, # split table by group
type = c(Fun, Motivation, Practiced_without_parent, Use_App_self_explanatory,
Use_Training_daily_life, Behav_Dealing_w_Feelings, Behav_Interest_Languages) ~ "continuous",
statistic = list(all_continuous() ~ "{mean} ({sd})", # descriptives definition
all_categorical() ~ "{n} / {N} ({p}%)"),
digits = all_continuous() ~ 2,
missing = "no" # don't list missing data separately
) %>%
add_n() %>% # add column with total number of non-missing observations
add_p() %>% # test for a difference between groups
modify_header(label = "**Variable**") %>% # update the column header
bold_labels()
# Print table
app_stats_table| Variable | N | Controls, N = 371 | Zirkus Empathico, N = 351 | p-value2 |
|---|---|---|---|---|
| My child enjoyed the training. | 72 | 4.00 (0.97) | 4.34 (0.87) | 0.11 |
| My child was motivated to do the training. | 72 | 3.78 (1.08) | 4.00 (1.16) | 0.3 |
| My child trained mostly without me. | 72 | 3.38 (1.23) | 3.11 (1.39) | 0.4 |
| The training was self-explanatory. | 72 | 3.86 (0.82) | 4.49 (0.66) | 0.001 |
| The training was compatible with daily routines. | 72 | 4.32 (0.85) | 4.31 (0.93) | >0.9 |
| My child copes better with its own feelings. | 72 | 2.24 (0.95) | 2.91 (0.98) | 0.008 |
| My child is more interested in other languages | 72 | 3.05 (1.45) | 1.51 (0.95) | <0.001 |
|
1
Mean (SD)
2
Wilcoxon rank sum test
|
||||
*Please note: 2 parental ratings are missing for this fidelity rating.
Acceptance
My child had / was…
# Select data for acceptibility questions
app_acc = as_tibble(app_qn)
app_acc = app_acc %>%
dplyr::select(Fun:Practiced_without_parent)
# Recode variable
app_acc = data.frame(lapply(app_acc, factor, ordered = TRUE, levels = 1:5, labels = c("Do not agree",
"Rather not agree", "Partly agree", "Rather agree", "Agree")))
# Add training info
app_acc$group = app_qn$App
# Separate by training / control group
app_acc_ZE = app_acc[app_acc$group == "ZE", ]
app_acc_SB = app_acc[app_acc$group == "CT", ]
app_acc_ZE = subset(app_acc_ZE, select = -c(group))
app_acc_SB = subset(app_acc_SB, select = -c(group))
# Combine data sets (account for different lengths of data frames)
comb_acc_app = merge(app_acc_SB, app_acc_ZE, by = "row.names", all = T, suffixes = c("",
""))
comb_acc_app$Row.names <- NULL
# Plot likert plot
plot_likert(comb_acc_app, catcount = 5, values = FALSE, wrap.legend.labels = 5, c(rep("Controls",
8), rep("Zirkus Empathico", 8)), geom.colors = c("#040a0b", "#1a3e43", "#2b6770",
"#80a4a9", "#bfd1d4"), rel_heights = c(9, 11), wrap.labels = 65, reverse.scale = TRUE,
show.n = FALSE, axis.labels = c("fun engaging with the app.", "motivated to train with the app.",
"frustrated during training.", "bored during training.", "wanted to play longer than agreed.",
"motivated by the app's rewards.", "difficulty understanding some of the app's content.",
"trained mostly without me."))
# http://www.sthda.com/english/wiki/text-mining-and-word-cloud-fundamentals-in-r-5-simple-steps-you-should-know
# https://cran.r-project.org/web/packages/ggwordcloud/vignettes/ggwordcloud.html
# Read txt files
text_CG_likes = readLines("./data/wc_CG_likes.txt")
text_CG_dislikes = readLines("./data/wc_CG_dislikes.txt")
text_TG_likes = readLines("./data/wc_TG_likes.txt")
text_TG_dislikes = readLines("./data/wc_TG_dislikes.txt")
# Load data as corpus
CG_likes = Corpus(VectorSource(text_CG_likes))
CG_dislikes = Corpus(VectorSource(text_CG_dislikes))
TG_likes = Corpus(VectorSource(text_TG_likes))
TG_dislikes = Corpus(VectorSource(text_TG_dislikes))What did your child like most about digital training?
# Build a term-document matrix
dtm = TermDocumentMatrix(CG_likes)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_CG_likes = data.frame(word = names(v), freq = v)
dtm = TermDocumentMatrix(TG_likes)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_TG_likes = data.frame(word = names(v), freq = v)
# Build word coulds
CG_likes_word = ggplot(d_CG_likes, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE, rm_outside = TRUE) + scale_size_area(max_size = 22) +
theme_minimal() + scale_color_gradient(low = "#041012", high = "#5fa7b3") + ggtitle("Controls")
TG_likes_word = ggplot(d_TG_likes, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE, rm_outside = TRUE) + scale_size_area(max_size = 22) +
theme_minimal() + scale_color_gradient(low = "#63430a", high = "#c48310") + ggtitle("Zirkus Empathico")
# Display plots
fig_like_words = cowplot::plot_grid(CG_likes_word, TG_likes_word, nrow = 2, rel_widths = c(1,
1))
fig_like_words
What did he/she like less?
# Build a term-document matrix
dtm = TermDocumentMatrix(CG_dislikes)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_CG_dislikes = data.frame(word = names(v), freq = v)
dtm = TermDocumentMatrix(TG_dislikes)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_TG_dislikes = data.frame(word = names(v), freq = v)
# Build word coulds
CG_dislikes_word = ggplot(d_CG_dislikes, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE, rm_outside = TRUE) + scale_size_area(max_size = 21) +
theme_minimal() + scale_color_gradient(low = "#041012", high = "#5fa7b3") + ggtitle("Controls")
TG_dislikes_word = ggplot(d_TG_dislikes, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE, rm_outside = TRUE) + scale_size_area(max_size = 21) +
theme_minimal() + scale_color_gradient(low = "#63430a", high = "#c48310") + ggtitle("Zirkus Empathico")
# Display plots
fig_like_words = cowplot::plot_grid(CG_dislikes_word, TG_dislikes_word, nrow = 2,
rel_widths = c(1, 1))
fig_like_words
What did your child find difficult while exercising? What did he or she possibly not understand?
# Read txt files
text_CG_diff = readLines("./data/wc_CG_diff.txt")
text_TG_diff = readLines("./data/wc_TG_diff.txt")
# Load data as corpus
CG_diff = Corpus(VectorSource(text_CG_diff))
TG_diff = Corpus(VectorSource(text_TG_diff))
# Build a term-document matrix
dtm = TermDocumentMatrix(CG_diff)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_CG_diff = data.frame(word = names(v), freq = v)
dtm = TermDocumentMatrix(TG_diff)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_TG_diff = data.frame(word = names(v), freq = v)
# Build word coulds
CG_diff_word = ggplot(d_CG_diff, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE) + scale_size_area(max_size = 18) + theme_minimal() +
scale_color_gradient(low = "#041012", high = "#5fa7b3") + ggtitle("Controls")
TG_diff_word = ggplot(d_TG_diff, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE) + scale_size_area(max_size = 18) + theme_minimal() +
scale_color_gradient(low = "#63430a", high = "#c48310") + ggtitle("Zirkus Empathico")
# Display plots
fig_diff_words = cowplot::plot_grid(CG_diff_word, TG_diff_word, nrow = 2, rel_widths = c(1,
1))
fig_diff_words
Usability
# Select data for acceptibility questions
app_usa = as_tibble(app_qn)
app_usa = app_usa %>%
dplyr::select(Use_App_self_explanatory:Use_Training_Stressful)
# Recode variable
app_usa = data.frame(lapply(app_usa, factor, ordered = TRUE, levels = 1:5, labels = c("Do not agree",
"Rather not agree", "Partly agree", "Rather agree", "Agree")))
# Add training info
app_usa$group = app_qn$App
# Separate by training / control group
app_usa_ZE = app_usa[app_usa$group == "ZE", ]
app_usa_SB = app_usa[app_usa$group == "CT", ]
app_usa_ZE = subset(app_usa_ZE, select = -c(group))
app_usa_SB = subset(app_usa_SB, select = -c(group))
# Combine data sets (account for different lengths of data frames)
comb_int_use = merge(app_usa_SB, app_usa_ZE, by = "row.names", all = T, suffixes = c("",
""))
comb_int_use$Row.names <- NULL
# Plot likert plot
plot_likert(comb_int_use, catcount = 5, values = FALSE, wrap.legend.labels = 5, c(rep("Controls",
5), rep("Zirkus Empathico", 5)), geom.colors = c("#121117", "#2e2b3b", "#5b5675",
"#7c7891", "#ceccd6"), rel_heights = c(8, 10), wrap.labels = 65, reverse.scale = TRUE,
show.n = FALSE, axis.labels = c("App was self-explanatory.", "The training manual was helpful.",
"Training was compatible the daily routines.", "I felt adequately supervised.",
"I was mentally stressed during the training."))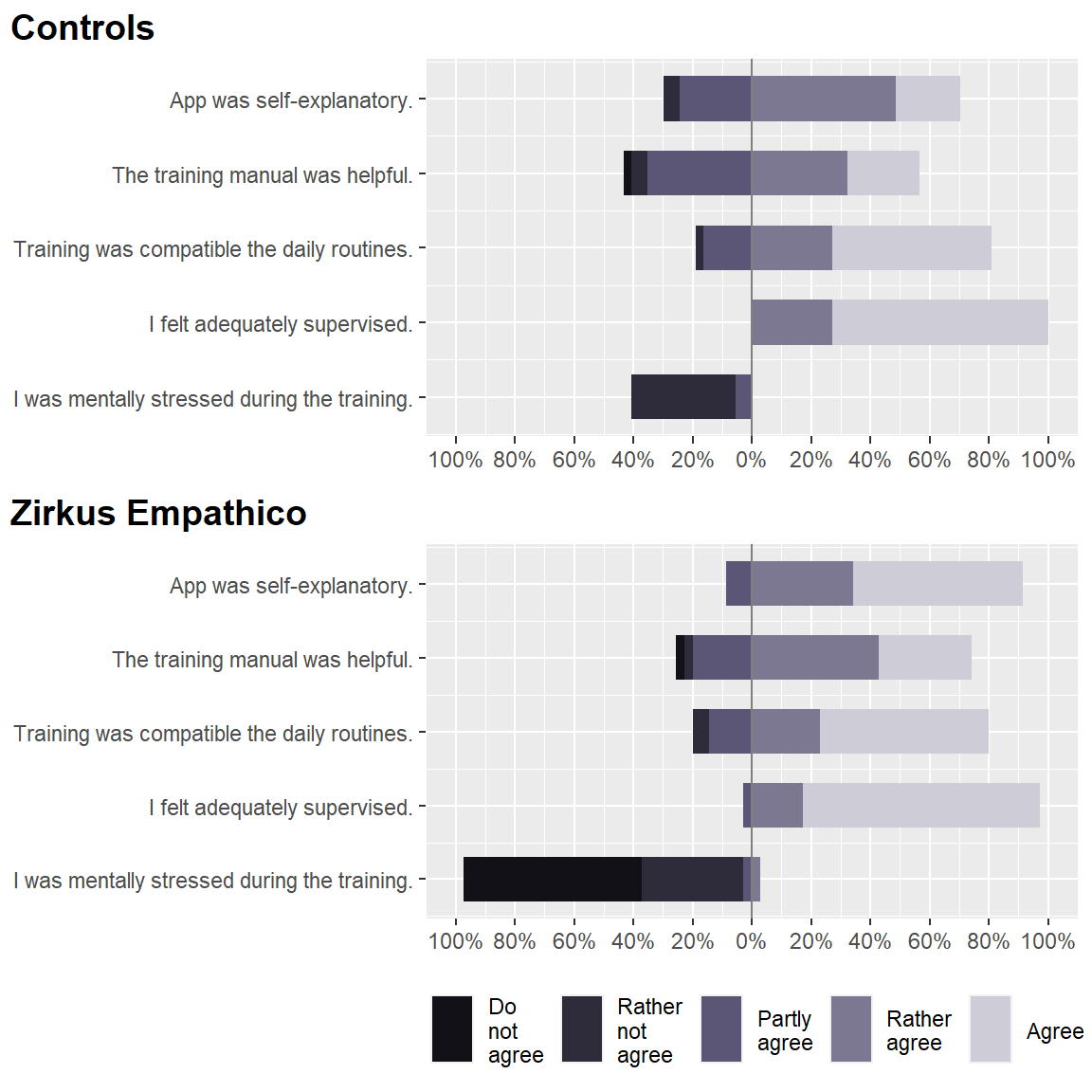
Perceived change after training
After completion of the training, me as dad/mom found that…
# Select data for acceptibility questions
app_beh = as_tibble(app_qn)
app_beh = app_beh %>%
dplyr::select(Behav_Interest_Feelings:Behav_Interest_Languages)
# Recode variable
app_beh = data.frame(lapply(app_beh, factor, ordered = TRUE, levels = 1:5, labels = c("Do not agree",
"Rather not agree", "Partly agree", "Rather agree", "Agree")))
# Add training info
app_beh$group = app_qn$App
# Separate by training / control group
app_beh_ZE = app_beh[app_beh$group == "ZE", ]
app_beh_SB = app_beh[app_beh$group == "CT", ]
app_beh_ZE = subset(app_beh_ZE, select = -c(group))
app_beh_SB = subset(app_beh_SB, select = -c(group))
# Combine data sets (account for different lengths of data frames)
comb_int_use = merge(app_beh_SB, app_beh_ZE, by = "row.names", all = T, suffixes = c("",
""))
comb_int_use$Row.names <- NULL
# Plot likert plot
plot_likert(comb_int_use, catcount = 5, values = FALSE, wrap.legend.labels = 5, c(rep("Controls",
9), rep("Zirkus Empathico", 9)), geom.colors = c("#23180d", "#583c22", "#9e6c3c",
"#c09369", "#d8bca1"), rel_heights = c(8, 10), wrap.labels = 65, reverse.scale = TRUE,
show.n = FALSE, axis.labels = c("my child shows more interest in feelings.",
"my child deals better with its own feelings.", "my child reacts more appropriately to others's feelings.",
"my child is more open-minded about his environment.", "my child spends more time with other children.",
"communication about feelings in our family improved.", "I have a better relationship with my child.",
"my child uses English words or phrases more often.", "my child is more interested in other languages."))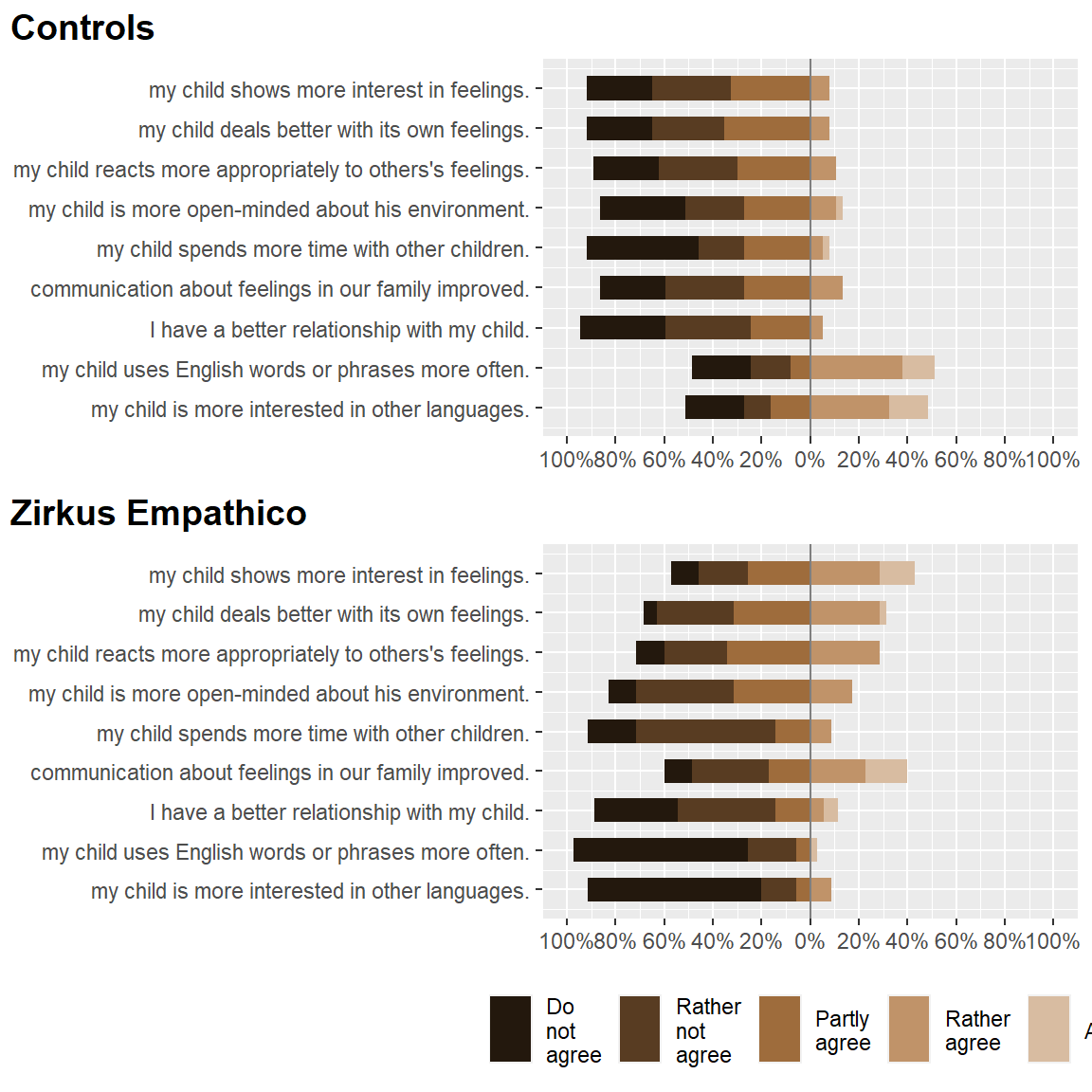
Has your child changed in terms of his or her behavior in school/kindergarten/family? If so, please describe how these changes manifested themselves.
# Read txt files
text_CG_chang = readLines("./data/wc_CG_chang.txt")
text_TG_chang = readLines("./data/wc_TG_chang.txt")
# Load data as corpus
CG_chang = Corpus(VectorSource(text_CG_chang))
TG_chang = Corpus(VectorSource(text_TG_chang))
# Build a term-document matrix
dtm = TermDocumentMatrix(CG_chang)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_CG_chang = data.frame(word = names(v), freq = v)
dtm = TermDocumentMatrix(TG_chang)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_TG_chang = data.frame(word = names(v), freq = v)
# Build word coulds
CG_chang_word = ggplot(d_CG_chang, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE, rm_outside = TRUE) + scale_size_area(max_size = 20) +
theme_minimal() + scale_color_gradient(low = "#041012", high = "#5fa7b3") + ggtitle("Controls")
TG_chang_word = ggplot(d_TG_chang, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE, rm_outside = TRUE) + scale_size_area(max_size = 20) +
theme_minimal() + scale_color_gradient(low = "#63430a", high = "#c48310") + ggtitle("Zirkus Empathico")
# Display plots
fig_chang_words = cowplot::plot_grid(CG_chang_word, TG_chang_word, nrow = 2, rel_widths = c(1,
1))
fig_chang_words
Parental involvement
How was your involvement in your child’s training (e.g. did your child tend to train alone or were you present the whole time, did you tend to observe or did you have to explain a lot)?
# Read txt files
text_CG_involv = readLines("./data/wc_CG_involv.txt")
text_TG_involv = readLines("./data/wc_TG_involv.txt")
# Load data as corpus
CG_involv = Corpus(VectorSource(text_CG_involv))
TG_involv = Corpus(VectorSource(text_TG_involv))
# Build a term-document matrix
dtm = TermDocumentMatrix(CG_involv)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_CG_involv = data.frame(word = names(v), freq = v)
dtm = TermDocumentMatrix(TG_involv)
m = as.matrix(dtm)
v = sort(rowSums(m), decreasing = TRUE)
d_TG_involv = data.frame(word = names(v), freq = v)
# Build word coulds
CG_involv_word = ggplot(d_CG_involv, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE, rm_outside = TRUE) + scale_size_area(max_size = 18) +
theme_minimal() + scale_color_gradient(low = "#041012", high = "#5fa7b3") + ggtitle("Controls")
TG_involv_word = ggplot(d_TG_involv, aes(label = word, size = freq, color = freq)) +
geom_text_wordcloud(area_corr = TRUE, rm_outside = TRUE) + scale_size_area(max_size = 18) +
theme_minimal() + scale_color_gradient(low = "#63430a", high = "#c48310") + ggtitle("Zirkus Empathico")
# Display plots
fig_involv_words = cowplot::plot_grid(CG_involv_word, TG_involv_word, nrow = 2, rel_widths = c(1,
1))
fig_involv_words
Session info
# Get session info
sessionInfo()R version 4.0.2 (2020-06-22)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 18362)
Matrix products: default
locale:
[1] LC_COLLATE=German_Germany.1252 LC_CTYPE=German_Germany.1252
[3] LC_MONETARY=German_Germany.1252 LC_NUMERIC=C
[5] LC_TIME=German_Germany.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] wordcloud_2.6 tm_0.7-8 NLP_0.2-1
[4] rmdformats_1.0.2 ggwordcloud_0.5.0 sjmisc_2.8.6
[7] sjstats_0.18.1 sjPlot_2.8.7 rstatix_0.7.0
[10] RColorBrewer_1.1-2 psych_2.1.3 plyr_1.8.6
[13] ppcor_1.1 MASS_7.3-53.1 pander_0.6.3
[16] jmv_1.2.23 ggpubr_0.4.0 GGally_2.1.1
[19] foreign_0.8-81 esci_0.1.1 emmeans_1.5.5-1
[22] eegUtils_0.5.0 corrplot_0.84 car_3.0-10
[25] carData_3.0-4 broom_0.7.6 afex_0.28-1
[28] lme4_1.1-26 Matrix_1.3-2 tadaatoolbox_0.17.0
[31] miceadds_3.11-6 mice_3.13.0 gtsummary_1.4.0
[34] expss_0.10.7 eeptools_1.2.4 XLConnect_1.0.3
[37] forcats_0.5.1 stringr_1.4.0 dplyr_1.0.5
[40] purrr_0.3.4 readr_1.4.0 tidyr_1.1.3
[43] tibble_3.1.1 ggplot2_3.3.3 tidyverse_1.3.1
[46] kableExtra_1.3.4
loaded via a namespace (and not attached):
[1] estimability_1.3 R.methodsS3_1.8.1 coda_0.19-4 knitr_1.32
[5] multcomp_1.4-16 R.utils_2.10.1 data.table_1.14.0 rpart_4.1-15
[9] generics_0.1.0 cowplot_1.1.1 TH.data_1.0-10 commonmark_1.7
[13] proxy_0.4-25 future_1.21.0 webshot_0.5.2 xml2_1.3.2
[17] lubridate_1.7.10 httpuv_1.5.5 assertthat_0.2.1 viridis_0.6.0
[21] xfun_0.22 hms_1.0.0 jquerylib_0.1.3 rJava_0.9-13
[25] evaluate_0.14 promises_1.2.0.1 fansi_0.4.2 dbplyr_2.1.1
[29] readxl_1.3.1 DBI_1.1.1 tmvnsim_1.0-2 htmlwidgets_1.5.3
[33] reshape_0.8.8 ellipsis_0.3.1 backports_1.2.1 signal_0.7-6
[37] bookdown_0.21 insight_0.13.2 jmvcore_1.2.23 vctrs_0.3.7
[41] sjlabelled_1.1.7 abind_1.4-5 withr_2.4.2 checkmate_2.0.0
[45] vcd_1.4-8 mnormt_2.0.2 svglite_2.0.0 cluster_2.1.2
[49] lazyeval_0.2.2 crayon_1.4.1 slam_0.1-48 labeling_0.4.2
[53] pkgconfig_2.0.3 nlme_3.1-152 vipor_0.4.5 nnet_7.3-15
[57] rlang_0.4.10 globals_0.14.0 lifecycle_1.0.0 miniUI_0.1.1.1
[61] sandwich_3.0-0 modelr_0.1.8 cellranger_1.1.0 matrixStats_0.58.0
[65] lmtest_0.9-38 boot_1.3-27 zoo_1.8-9 reprex_2.0.0
[69] base64enc_0.1-3 beeswarm_0.4.0 png_0.1-7 viridisLite_0.4.0
[73] ini_0.3.1 parameters_0.13.0 rootSolve_1.8.2.1
[ reached getOption("max.print") -- omitted 90 entries ]